Research
Hi👋, I’m Tianjian! I’m a PhD student in Computer Science at Johns Hopkins University, proudly advised by Prof. Daniel Khashabi. I am also a research scientist intern at Meta FAIR, where I had the privilege to be advised by Tianlu Wang in Summer 2025 and Weizhe Yuan in Summer 2026.
Previously, I completed my Master’s degree in Computer Science at JHU. I worked with my wonderful advisors Kenton Murray and Philipp Koehn. Before that, I was an undergraduate at New York University.
My research lies at the intersection between machine learning and natural language processing. I prefer solutions that are simple, generalizable, and theoretically sound.
If you have anything to share with me, please feel free to contact me through my email: tli104 at jhu.edu

Updates
June 2026. We released Self-Compacting Language Model Agents, a method that lets an agent decide when and how to compact its own context.
April 2026. We released Many-Tier Instruction Hierarchy in LLM Agents, studying how agents resolve conflicting instructions across 12+ privilege levels.
March 2026. We released ParaGator, which trains parallel reasoning end-to-end: the generator learns to produce diverse candidates with pass@k while the aggregator learns to synthesize them into a final answer with pass@1, giving large gains on competition math and scientific reasoning.
March 2026. I will be returning to Meta FAIR in NYC as a research scientist intern in Summer 2026.
September 2025. We released Darling, an RL method that makes language models generate diverse outputs without sacrificing quality.
May 2025. We released SimpleMix, a study of the interplay between on- and off-policy data in preference optimization, accepted to ICML 2025.
January 2025. We had three papers accepted to NAACL 2025, on imbalanced training, verbatim quoting, and model creativity.
December 2024. I will be joining Meta FAIR as a research scientist intern in Summer 2025.
Selected Works
Tianjian Li, Jingyu Zhang, William Jurayj, Xi Wang, Chuanyang Jin, Mehrdad Farajtabar, Eric Nalisnick, Daniel Khashabi
arXiv preprint · Code
We let the model itself decide when and how to compact its own context, pairing a compaction tool with a lightweight rubric for when to fire and when to hold off. This self-compaction matches or beats fixed-interval summarization while using 30-70% less context budget.
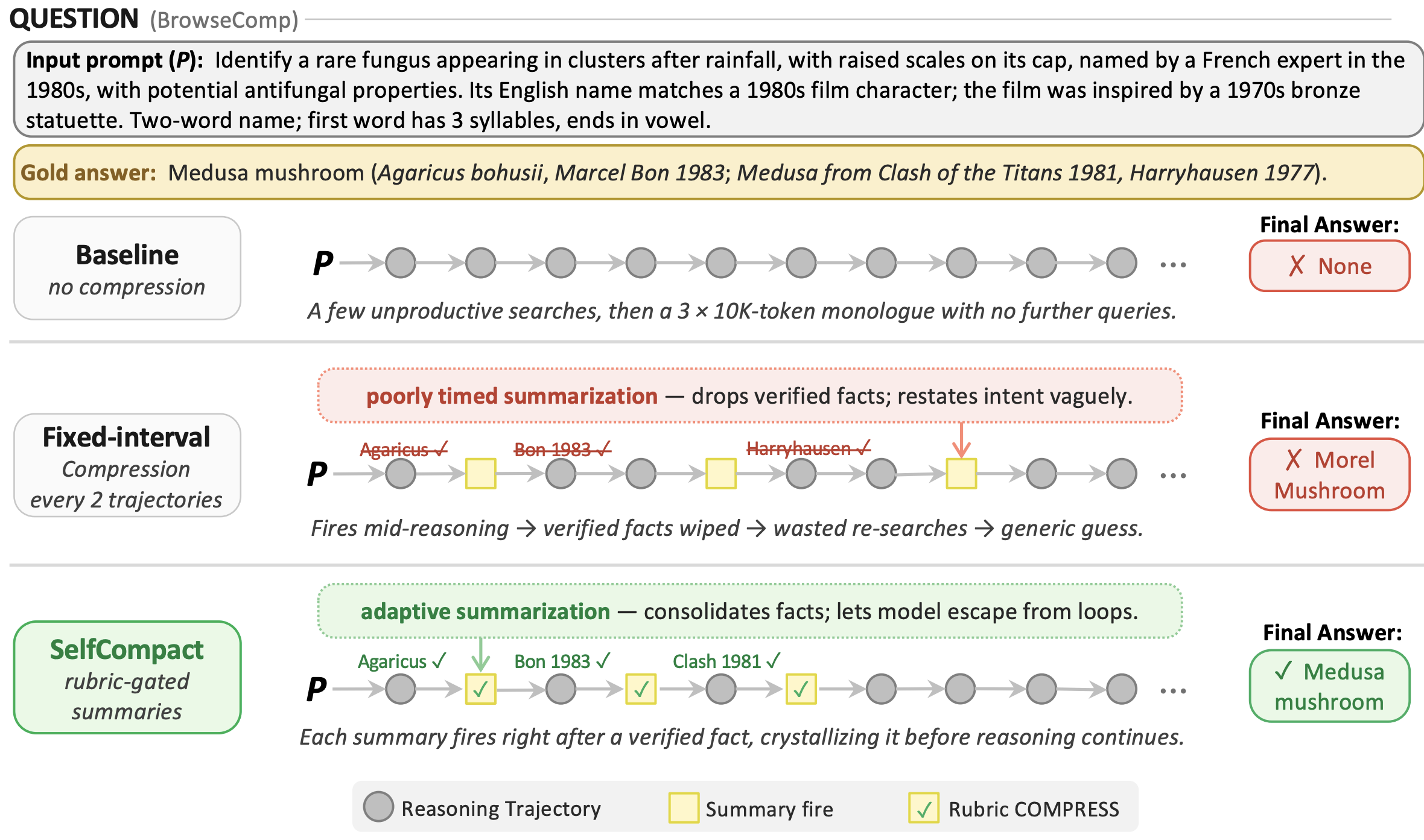
Tianjian Li, Jingyu Zhang, Ping Yu, Swarnadeep Saha, Sainbayar Sukhbaatar, Jason Weston, Ilia Kulikov, Jack Lanchantin
arXiv preprint
We study parallel reasoning, where a generator proposes multiple candidate solutions and an aggregator synthesizes them into a final answer. ParaGator trains both stages together end-to-end: the generator is optimized for diverse candidates with pass@k while the aggregator is optimized with pass@1, yielding large gains on competition math and scientific reasoning.
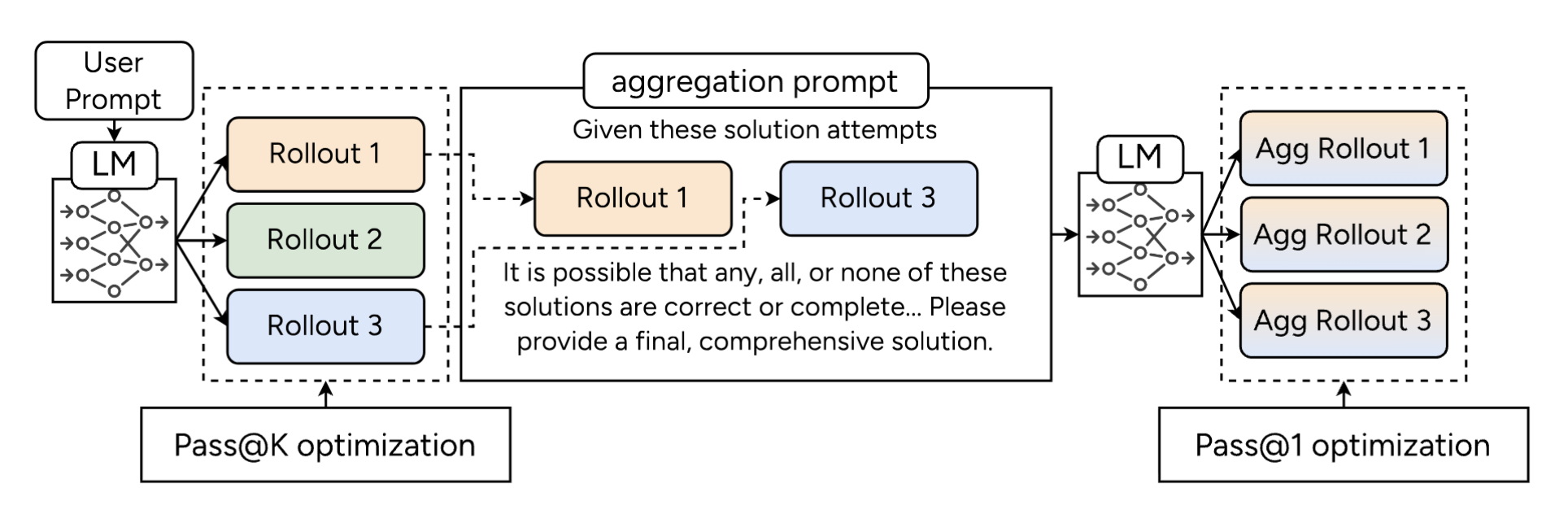
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, Tianlu Wang
Scaling Post-Training (SPOT) Workshop, ICLR 2026 · Code
We propose Darling, an online reinforcement learning method that jointly optimizes for the diversity and quality of language model generations. Darling encourages models to produce varied outputs without sacrificing correctness, improving performance on open-ended generation tasks.
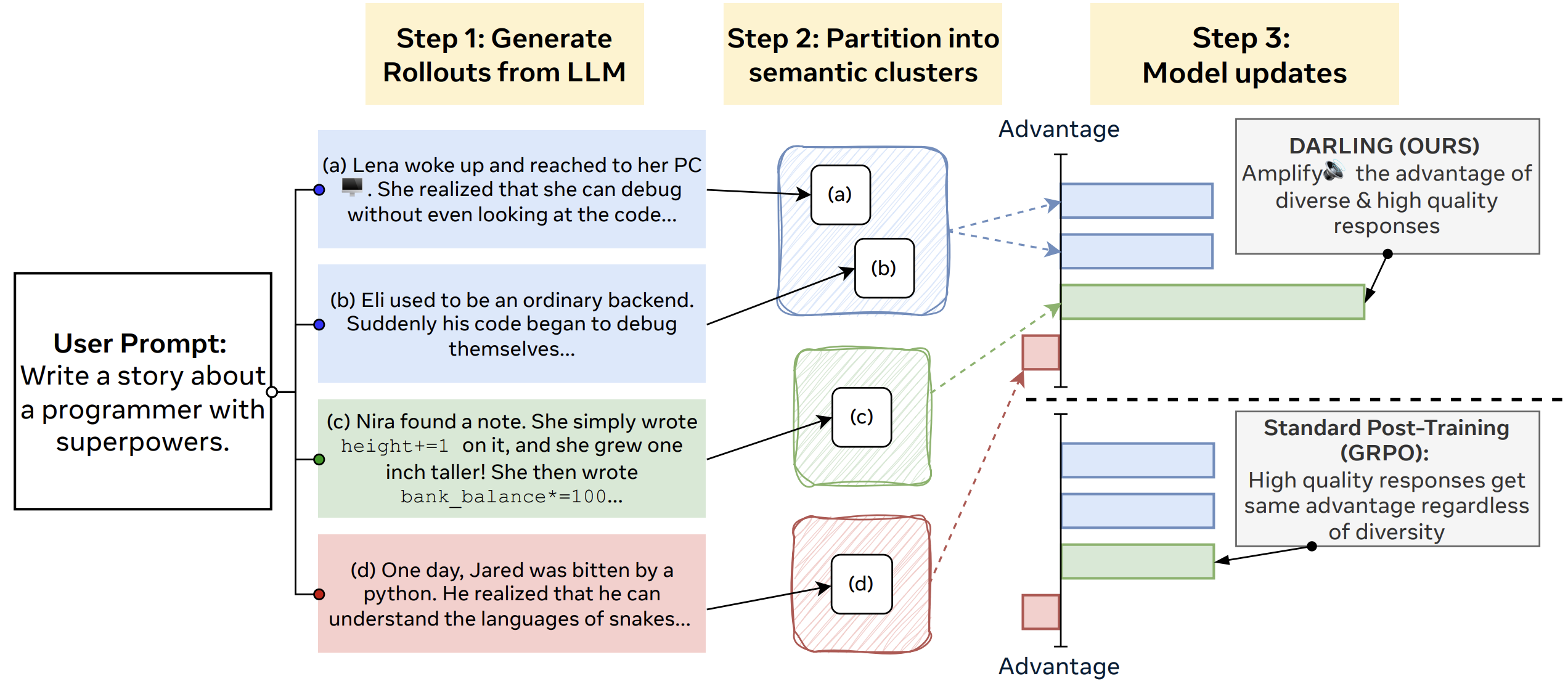
Tianjian Li, Haoran Xu, Philipp Koehn, Daniel Khashabi, Kenton Murray
ICLR 2024. Spotlight Presentation - Top 5% · Code
We propose Error Norm Truncation, a robust training objective that down-weights noisy training examples using a more accurate estimate of sample quality than the loss alone. It improves the quality and robustness of text generation models across machine translation, summarization, and language modeling.
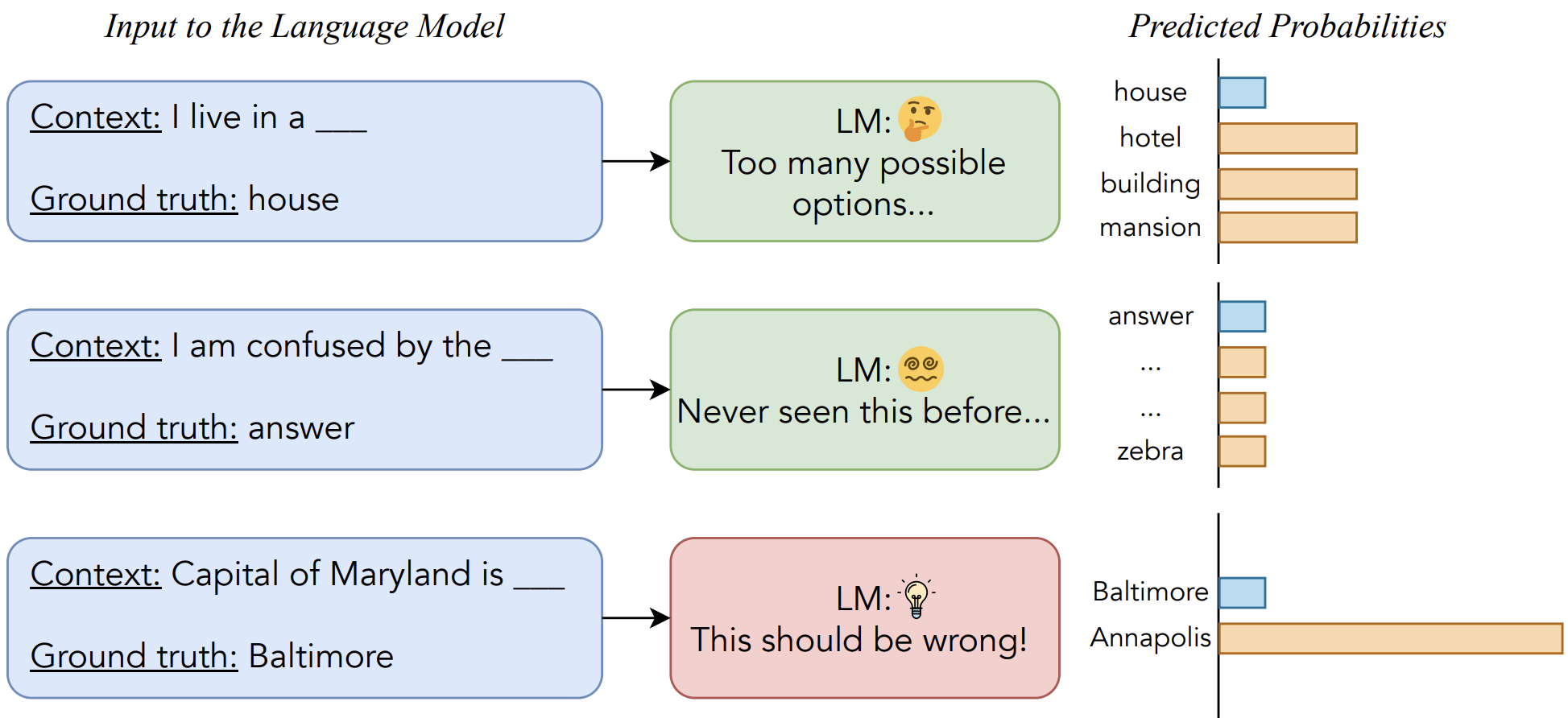
Full Publications
Self-Compacting Language Model Agents. Tianjian Li, Jingyu Zhang, William Jurayj, Xi Wang, Chuanyang Jin, Mehrdad Farajtabar, Eric Nalisnick, Daniel Khashabi. arXiv preprint.
ThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions. Chuanyang Jin, Binze Li, Haopeng Xie, Cathy Mengying Fang, Tianjian Li, Shayne Longpre, Hongxiang Gu, Maximillian Chen, Tianmin Shu. Best Paper Award, RLxF Workshop, ICML 2026.
Many-Tier Instruction Hierarchy in LLM Agents. Jingyu Zhang, Tianjian Li, William Jurayj, Hongyuan Zhan, Benjamin Van Durme, Daniel Khashabi. arXiv preprint.
Reasoning over Mathematical Objects: On-Policy Reward Modeling and Test Time Aggregation. Pranjal Aggarwal, Marjan Ghazvininejad, Seungone Kim, Ilia Kulikov, Jack Lanchantin, Xian Li, Tianjian Li, Bo Liu, Graham Neubig, Anaelia Ovalle, Swarnadeep Saha, Sainbayar Sukhbaatar, Sean Welleck, Jason Weston, Chenxi Whitehouse, Adina Williams, Jing Xu, Ping Yu, Weizhe Yuan, Jingyu Zhang, Wenting Zhao. arXiv preprint.
Jointly Reinforcing Diversity and Quality in Language Model Generations. Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, Tianlu Wang. Scaling Post-Training (SPOT) Workshop, ICLR 2026.
The Translation Barrier Hypothesis: Multilingual Generation with Large Language Models Suffers from Implicit Translation Failure. Niyati Bafna, Tianjian Li, Kenton Murray, David R. Mortensen, David Yarowsky, Hale Sirin, Daniel Khashabi. IJCNLP-AACL 2025.
The Flaw of Averages: Quantifying Uniformity of Performance on Benchmarks. Arda Uzunoglu, Tianjian Li, Daniel Khashabi. arXiv preprint.
SIMPLEMIX: Frustratingly Simple Mixing of Off- and On-policy Data in Language Model Preference Learning. Tianjian Li, Daniel Khashabi. ICML 2025.
Upsample or Upweight? Balanced Training on Heavily Imbalanced Datasets. Tianjian Li, Haoran Xu, Weiting Tan, Kenton Murray, Daniel Khashabi. NAACL 2025.
Benchmarking Language Model Creativity: A Case Study on Code Generation. Yining Lu, Dixuan Wang, Tianjian Li, Dongwei Jiang, Daniel Khashabi. NAACL 2025.
Verifiable by Design: Aligning Language Models to Quote from Pre-Training Data. Jingyu Zhang, Marc Marone, Tianjian Li, Benjamin Van Durme, Daniel Khashabi. NAACL 2025.
Error Norm Truncation: Robust Training in the Presence of Data Noise for Text Generation Models. Tianjian Li, Haoran Xu, Philipp Koehn, Daniel Khashabi, Kenton Murray. ICLR 2024. Spotlight Presentation - Top 5%.
Why Does Zero-shot Cross-lingual Generation Fail? An Explanation and A Solution. Tianjian Li, Kenton Murray. ACL 2023 (Findings).
Invited Talks
Jan 2026. Invited talk on Darling at Beijing Academy of Artificial Intelligence (BAAI).
Spring 2024. Invited talk on Error Norm Truncation at Johns Hopkins University, CLSP Seminar.
Misc
I am a fan of: Cold Brew, Badminton, Go, Chinese Chess, DOTA 2, Dylan Harper, and Michael Olise.